Ich habe zwei Dateien A - nodes_to_delete und B - nodes_to_keep. Jede Datei hat mehrere Zeilen mit numerischen IDs.bash, Linux: Unterschied zwischen zwei Textdateien einstellen
Ich möchte die Liste der numerischen IDs haben, die in nodes_to_delete sind, aber nicht in nodes_to_keep, z. alt text http://mathworld.wolfram.com/images/equations/SetDifference/Inline1.gif.
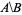{kind=link}
In einer PostgreSQL-Datenbank zu tun ist unangemessen langsam. Irgendein einfacher Weg, es in bash mit Linux CLI-Tools zu tun?
UPDATE: Dies scheint ein Pythonic Job zu sein, aber die Dateien sind wirklich, wirklich groß. Ich habe einige ähnliche Probleme unter Verwendung von uniq, sort und einigen Mengenlehretechniken gelöst. Dies war etwa zwei oder drei Größenordnungen schneller als die Datenbankäquivalente.
Ich bin neugierig, was Antworten kommen werden. Bash ist ein bisschen mehr segphault, Systemadministrator glaube ich. Wenn du "in python" oder "in php" gesagt hättest oder was auch immer deine Chancen gewesen wären :) – extraneon
Ich sah den Titel und war bereit, UI-Inkonsistenzen und heiliger-als-du-Hilfe-Foren zu bahsen. Das hat mich enttäuscht, als ich die eigentliche Frage gelesen habe. :( – aehiilrs