6
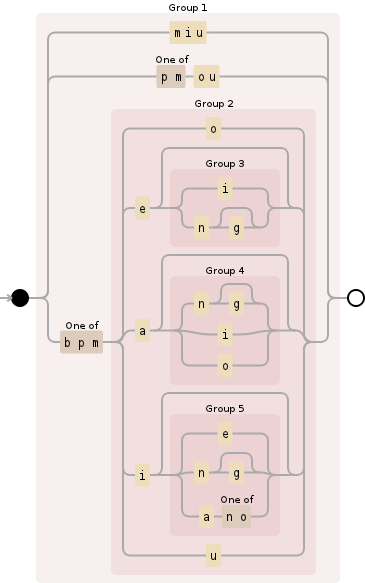
Ich suche nach einem regulären Ausdruck, der korrekt gültiges Pinyin (z. B. "sheng", "sou") entsprechen kann (beim Ignorieren ungültiger Pinyin, zB "shong", "sei") Die in den Google-Suchergebnissen angegebenen Ergebnisse stimmen in einigen Fällen mit dem ungültigen pinyin überein.Regex für passendes Pinyin
Offensichtlich ist dies ein Monster-Regex, egal, welchen Ansatz man wählt, und ich bin besonders an den verschiedenen Ansätzen zur Lösung dieses Problems interessiert .. Zum Beispiel: "Optimizing a regular expression to parse chinese pinyin" verwendet lookbacks
Eine Tabelle gültiger Pinyin ist hier zu finden: http://pinyin.info/rules/initials_finals.html
Sie sagen, dass "sou" sowohl gültig als auch ungültig ist. – mareoraft
Schöner Fang. "Sou" ist gültig, also habe ich den zweiten zu "sei" geändert, was ein ungültiger Pinyin ist. – stevendaniels
Große Frage. Für praktische Anwendungen hat eine Nachschlagetabelle mehrere Vorteile gegenüber einer Regex. –