Ja, Prüfpunkten ist eine blockierende Operation, so dass er die Verarbeitung während seiner Tätigkeit stoppt. Die Zeitdauer, für die die Berechnung durch diese Serialisierung des Status angehalten wird, hängt von der Schreibleistung des Mediums ab, auf dem Sie dies schreiben (haben Sie von Tachyon/Alluxio gehört?).
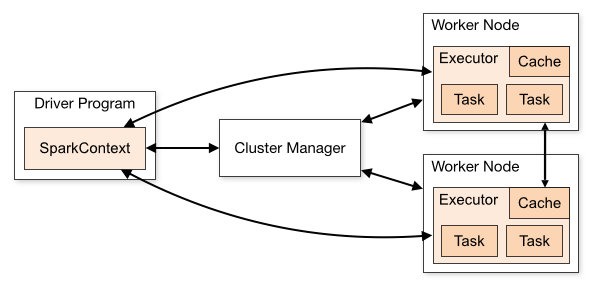
Auf der anderen Seite wird vor Prüfpunkt-Daten lesen auf nicht jede neue Prüfpunkten Betrieb: die Stateful-Informationen bereits in Spark Cache gehalten wird als der Strom bei betrieben wird (Checkpoints sind nur ein Backup es). Stellen wir uns einen möglichst einfachen Zustand vor, eine Summe aller ganzen Zahlen, die in einem Strom von ganzen Zahlen zusammentreffen: Sie berechnen für jede Menge einen neuen Wert für diese Summe, basierend auf den Daten, die Sie im Stapel sehen - und Sie können diese partielle Summe speichern im Cache (siehe oben). Alle fünf Lose (abhängig von Ihrem Prüfintervall) schreiben Sie diese Summe auf die Festplatte. Wenn Sie nun einen Executor (eine Partition) in einem nachfolgenden Batch verlieren, können Sie die Summe dafür rekonstruieren, indem Sie nur die Partitionen für diesen Executor für bis zu die letzten fünf Partitionen neu verarbeiten (durch Lesen der Festplatte, um den letzten Checkpoint zu finden) und die fehlenden Teile der letzten bis zu fünf Chargen erneut zu verarbeiten. Bei normaler Verarbeitung (keine Vorfälle) müssen Sie nicht auf die Festplatte zugreifen.
Es gibt keine allgemeine Formel, die ich kenne, da Sie die maximale Datenmenge reparieren müssten, von der Sie sich erholen möchten. Die alte Dokumentation gibt a rule of thumb.
Aber im Fall von Streaming, können Sie Ihre Batch-Intervall wie eine Berechnung Budget denken. Angenommen, Sie haben ein Stapelintervall von 30 Sekunden. Auf jeder Charge haben Sie 30 Sekunden Zeit, um sie auf die Festplatte zu schreiben oder sie zu berechnen (Batch-Verarbeitungszeit). Um sicherzustellen, dass Ihr Job stabil ist, müssen Sie sicherstellen, dass die Stapelverarbeitungszeit nicht über das Budget hinausgeht. Andernfalls füllen Sie den Speicher Ihres Clusters (wenn Sie 30 Sekunden für die Verarbeitung und das "Leeren" von 30 Sekunden benötigen) Bei jeder Charge nehmen Sie mehr Daten auf, als während der gleichen Zeit gespült werden - da Ihr Speicher endlich ist, führt dies schließlich zu einer Überfüllung.
Nehmen wir an, Ihre durchschnittliche Stapelverarbeitungszeit beträgt 25 Sekunden. Sie haben also für jede Charge 5 Sekunden nicht zugewiesene Zeit in Ihrem Budget. Sie können das für den Checkpointing verwenden. Überlegen Sie nun, wie lange Sie das Checkpointing braucht (Sie können dies aus der Spark UI herausholen). 10 Sekunden ? 30 Sekunden ? Eine Minute ?
Wenn es Ihnen c Sekunden dauert auf einem bi Sekunden Batch-Intervall einen Checkpoint mit einer bp Sekunden Batch-Verarbeitungszeit, werden Sie „erholen“ von Prüfpunktverfahrens (Prozess der Daten, die noch in während dieser Zeit keine Verarbeitung kommt) in :
ceil(c/(bi - bp)) Chargen.
Wenn es Ihnen k Chargen nimmt von Prüfpunkten zu „erholen“ (dh das Zuspätkommen vom Checkpoint induziert zu erholen), und Sie sind Prüfpunktverfahrens alle p Chargen, müssen Sie sicherstellen, dass Sie k < p erzwingen, einen instabilen Job zu vermeiden . In unserem Beispiel:
so, wenn es Sie 10 Sekunden, um einen Prüfpunkt nimmt, wird es dauern Sie 10/(30 - 25) = 2 Chargen zu erholen, so dass Sie alle 2 Chargen Checkpoint (oder mehr, dh weniger häufig, was ich für einen ungeplanten Zeitverlust empfehlen würde).
Wenn Sie also 30 Sekunden zum Checkpoint brauchen, werden 30/(30 - 25) = 6 Chargen benötigt, um die Daten wiederherzustellen, so dass Sie alle 6 Chargen (oder mehr) überprüfen können.
Wenn Sie 60 Sekunden zum Prüfpunkt brauchen, können Sie alle 12 Chargen (oder mehr) prüfen.
Beachten Sie, dass dies Ihre Prüfpunkten Zeit davon ausgegangen, konstant ist, oder zumindest durch eine maximale Konstante beschränkt werden. Leider ist dies oft nicht der Fall: Ein häufiger Fehler besteht darin, zu vergessen, einen Teil des Zustands in statusbehafteten Datenströmen zu löschen, z. B. updateStatebyKey oder mapWithState - dennoch sollte die Größe des Zustands immer begrenzt sein. Beachten Sie, dass bei einem Multitenant-Cluster die Zeit für das Schreiben auf Festplatte nicht immer konstant ist. Andere Jobs versuchen möglicherweise, gleichzeitig auf demselben Executor auf die Festplatte zuzugreifen, was Sie von den Festplatten-Iops abhält (in this talk) > 5 gleichzeitige Schreib-Threads).
Hinweis: Sie sollten das Prüfpunktintervall festlegen, da der Standardwert der erste Stapel ist, der mehr als default checkpoint interval - d. H. 10s - nach dem letzten Stapel auftritt. Für unser Beispiel eines 30s-Batch-Intervalls bedeutet das, dass Sie jeden zweiten Batch checken. Oft ist es aus Gründen der reinen Fehlertoleranz zu häufig (wenn die erneute Verarbeitung einiger Chargen nicht so teuer ist), selbst wenn dies nach Ihrem Berechnungsbudget zulässig ist, und führt zu folgenden Spikes im Leistungsdiagramm:
