Ich bin stecken, wie man ein Problem löst. Ich habe eine Matrix mit folgendem Format:schreibe Werte für ähnliche Zeilen
Sequence Position Raw Binding (log ratio)
UC001AOZ.3 146 -0.746
UC001AOZ.3 147 -1.27
UC001AOZ.3 148 -1.66
UC001AOZ.3 149 -2.16
UC001AOZ.3 150 -2.08
... ... ...
UC222AOF.2 5000 1.22
UC222AOF.2 146 -1.12
UC222AOF.2 147 -1.41
... ... ...
UC222AOF.2 5000 5.13
... ... ...
Die erste Spalte (Sequence) beschreibt Gene nach diesen kryptischen Namen. Die zweite Spalte ist eine Position innerhalb des menschlichen Genoms und die dritte Spalte bezieht sich auf einen Wert für ein Ereignis.
Die Position geht bis 5000 und beginnt dann bei 146 erneut für das nächste Gen (siehe Format, zweiter Genname "UC222AOF.2"). Insgesamt gibt es 250 Gene mit 4854 Positionen und entsprechenden Raw Biding-Werten.
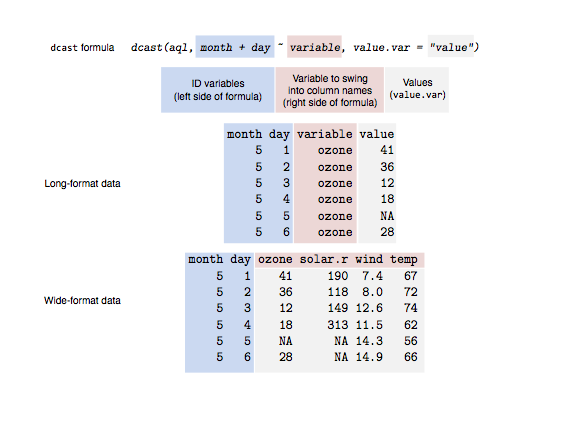
Ich möchte Mittelwerte aller Raw Bindung (log-Verhältnis) Werte an den Positionen zwischen 146 und 5000.
Eine Möglichkeit könnte wie folgt aussehen erhalten (Werte können als oben abweichen):
146 147 148 149 ... 5000
UC001AOZ.3 -0.746 -1.27 -1.66 -2.16 ... 1.22
UC222AOF.2 -1.12 -1.41 -1.31 -1.81 ... 5.13
UC002BW1.1 -0.112 -0.31 -0.51 -1.01 ... 1.01
Ich bin kein R regelmäßig aber einige Grundlagen kennen. Vielen Dank im Voraus!
{kind=link}
Guter Start für solide Antworten zu erhalten: http://StackOverflow.com/Questions/5963269/How-to-Make-Agreat-R-reproducible-Beispiel – snoram
Es scheint, Sie können dooda.Table' und tun 'DT [Position> = 146, Mittelwert (Rohbindung (log ratio))] ' – snoram
Vielen Dank für diesen hilfreichen Link! Ich habe hier ein Beispiel hochgeladen http://www.filehosting.org/file/details/589167/sample.tab –